LLM 캐시 최적화 완전 정복: KV 캐시·프롬프트 캐시·임베딩 캐시로 지연·비용 50% 줄이기
LLM 캐시를 제대로 설계하면 응답 지연은 짧아지고, 월 비용은 예측 가능해집니다. 본 글은 LLM 캐시 핵심 개념부터 KV 캐시·프롬프트 캐시·결과 캐시·임베딩 캐시·검색 캐시를 아우르는 아키텍처와 구현 패턴, 만료 전략, 측정·운영 포인트까지 한 번에 정리한 실전 가이드입니다.
LLM 캐시를 5가지 레이어(KV/프롬프트/결과/임베딩/검색)로 나눠 설명하고, TTL·키 설계·정합성·버전 관리·A/B 실험까지 다룹니다. Python/Node 예제 코드와 대시보드 지표, 팀에서 바로 도입할 체크리스트를 포함했습니다.
목차
1. 왜 지금 LLM 캐시인가
2. 캐시 유형 지도: 5가지 레이어
3. 키 설계·TTL·정합성 전략
4. 구현 예제(Python/Node)
5. 관찰성·A/B·비용 계산법
6. FAQ와 체크리스트
1. 왜 지금 LLM 캐시인가
핵심 요약: "낭비되는 토큰"을 줄이면 성능도 비용도 동시에 좋아진다.
대부분의 프로덕션 환경은 동일·유사 요청이 반복됩니다. 동일한 시스템 프롬프트, 유사한 사용자 질문, 동일한 검색 결과가 매일 쌓입니다. LLM 캐시는 이런 중복을 제거하여 지연(latency)과 비용(cost per task)을 함께 낮춥니다. 특히 RAG·에이전트 워크플로처럼 여러 호출이 연쇄되는 구조에서는 캐시 미세 튜닝만으로도 체감 효과가 큽니다.
LLM 캐시의 장점은 ① 반복 응답 시간 단축, ② 비용 절감, ③ 일관성·재현성 향상, ④ 장애 시 폴백 소스 역할입니다. 단, 과도한 캐시는 오정보 고착과 시계열 데이터의 신선도 하락을 유발할 수 있어 TTL·버전 전략이 필수입니다.
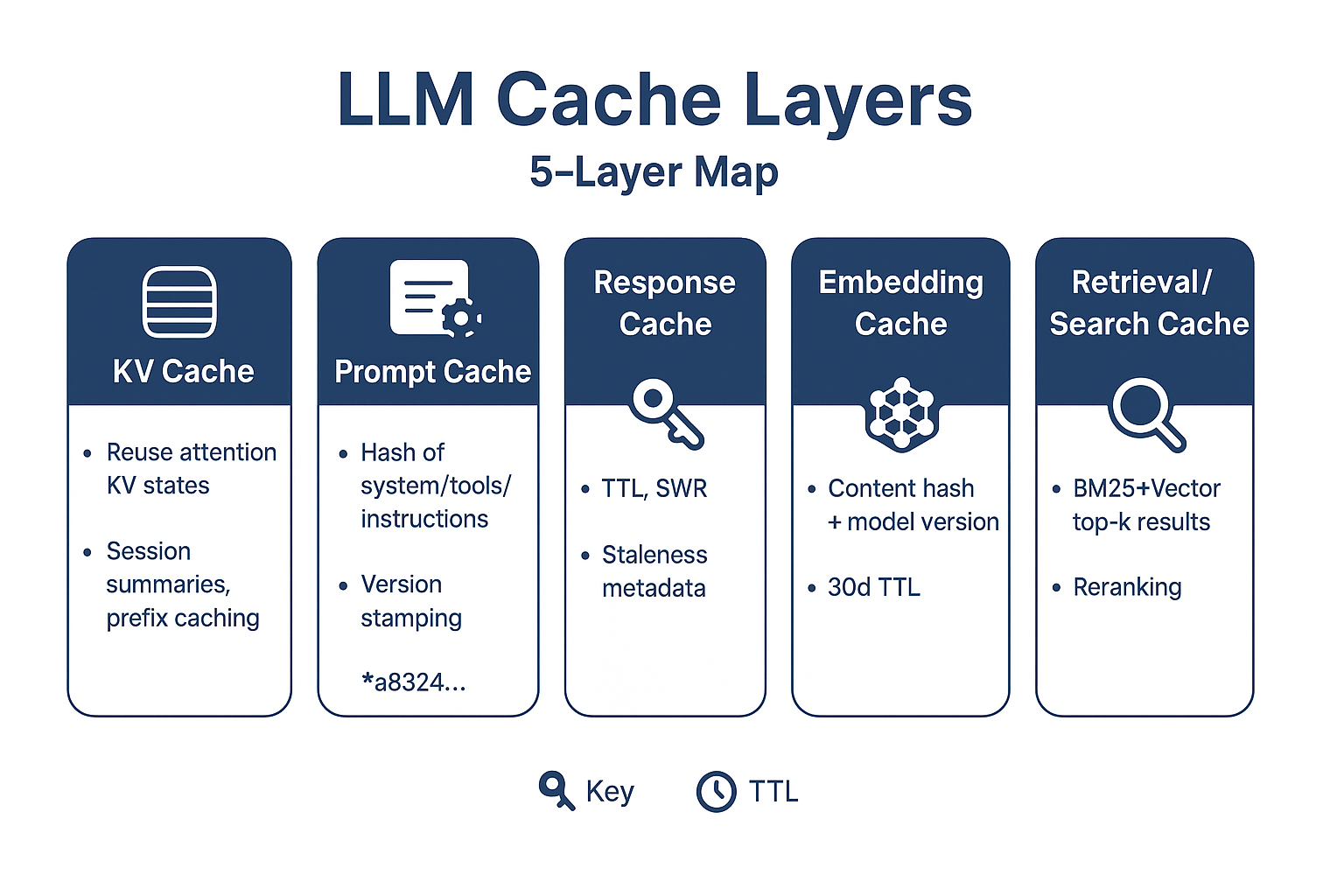
2. 캐시 유형 지도: 5가지 레이어
핵심 요약: 레이어를 분리하면 제어와 디버깅이 쉬워진다.
2.1 KV 캐시(Key-Value Cache)
- 무엇: 모델 내부의 키/값 주의(K/V) 상태를 재사용하거나, 외부에서 대화 이력을 압축 요약해 컨텍스트로 재활용하는 방식.
- 언제: 긴 문맥을 반복 확장할 때, 챗봇의 연속 대화, 스트리밍 생성에서 효과적.
- 주의: 대화 경계가 바뀌면 캐시 무효화. 사용자별/세션별 키 네임스페이스 분리.
2.2 프롬프트 캐시(Prompt Cache)
- 무엇: system + tools + instructions + normalized user input 조합 문자열을 해시 키로 프롬프트 캐시.
- 언제: 동일 템플릿과 유사 입력(FAQ, 문서 요약, 코드 스타일 변환).
- 주의: 프롬프트 버전(p:v3), 모델 버전(m:gptX), 파라미터(t:0.2)를 키에 포함.

2.3 결과 캐시(Response/Answer Cache)
- 무엇: 모델 최종 출력(JSON/텍스트)을 TTL과 함께 저장.
- 언제: 일·주 단위로 변하지 않는 결과(가이드, 정책, 튜토리얼) 제공 시.
- 주의: 출처 시점(staleness) 메타데이터 저장. RAG라면 인용 문서 해시를 포함.
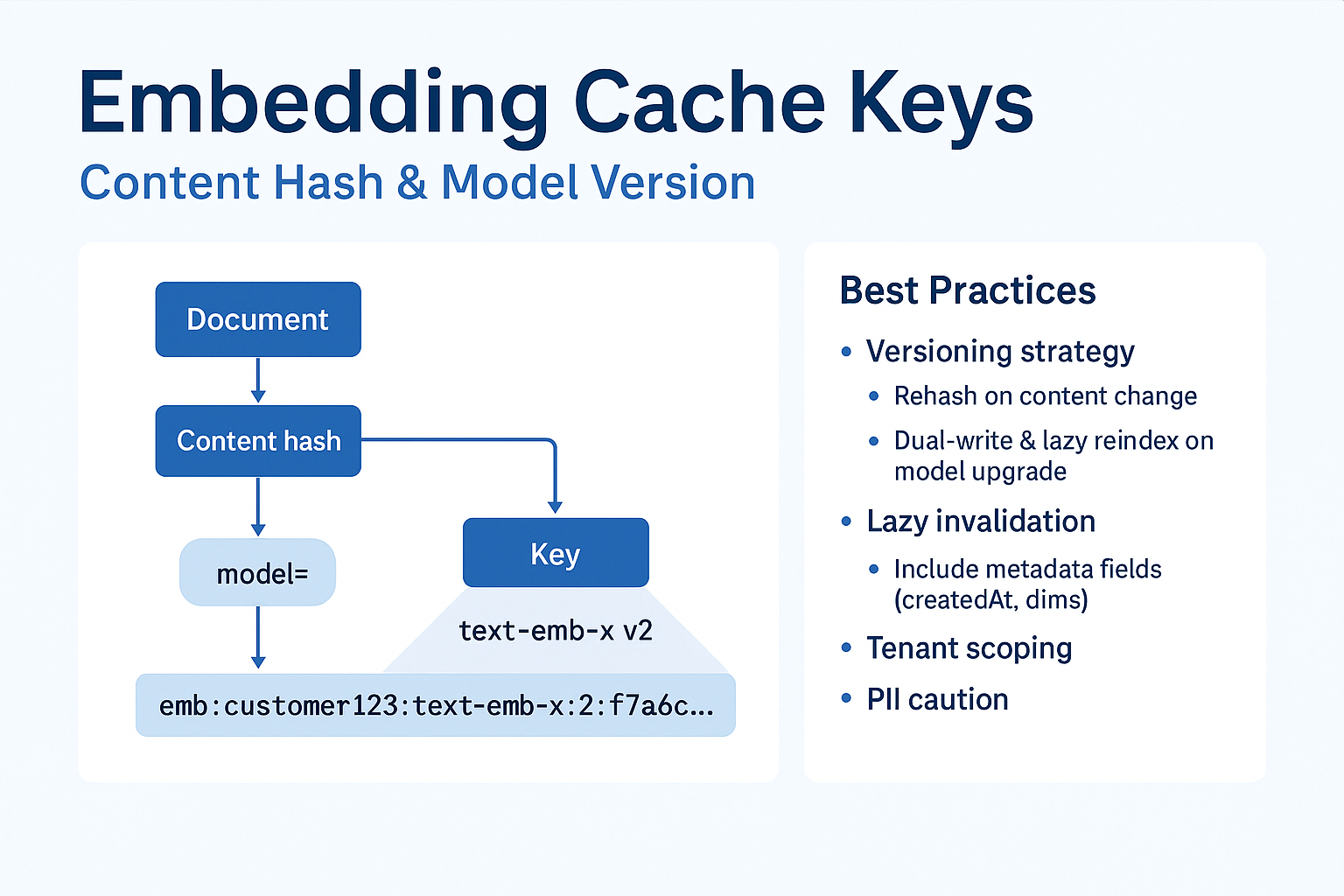
2.4 임베딩 캐시(Embedding Cache)
- 무엇: 같은 문서/문장에 대한 임베딩을 재사용.
- 언제: 정적 문서 컬렉션, 반복 인덱싱.
- 주의: 문서 콘텐츠 해시와 임베딩 모델 버전을 키에 포함. 모델 교체 시 전환 플랜 필요.
2.5 검색 캐시(Retrieval/Search Cache)
- 무엇: 동일 쿼리에 대한 검색 후보 목록/리랭크 결과를 저장.
- 언제: 트래픽 피크 타임, 동일 FAQ가 반복 조회될 때.
- 주의: 사용자 권한·필터(팀/제품/버전 등)를 키에 포함해야 보안 누수가 없다.
3. 키 설계·TTL·정합성 전략
핵심 요약: 키는 "입력·버전·정책"을 모두 반영해야 한다.
3.1 키 네이밍 규칙
<namespace>:<tenant>:<usecase>:<model>:<promptVer>:<paramHash>:<inputHash>
예) llm:acme:faq:gptX:p3:t02:sha256(...)
- 네임스페이스: llm, rag, emb, retr 등 레이어별 구분.
- 테넌트/사용자: B2B 멀티테넌트라면 필수.
- 버전/파라미터: 프롬프트/모델/온도/토큰 한도.
- 입력 해시: 정규화(normalization) 후 해시.
3.2 TTL·무효화(Invalidation)
- 정적 결과: 7~30일 TTL + 수동 퍼지(핫픽스 시).
- 반정적 결과: 1~24시간 TTL + 하위 리소스 변경 이벤트로 퍼지.
- 동적 결과: 분 단위 TTL 또는 캐시 미사용.
3.3 일관성·정합성
- Stale-While-Revalidate(SWR): 캐시된 응답을 즉시 제공하고 백그라운드에서 갱신.
- ETag/해시 정합성: RAG는 인용 문서의 콘텐츠 해시를 키에 섞어 정합성 보장.
- 권한 경계: 사용자/조직 ACL을 키에 포함하거나 캐시 엔트리에 바인딩.
4. 구현 예제(Python/Node)
핵심 요약: "정규화 → 키 생성 → 조회 → 미스 시 생성 → 저장"의 표준 래퍼를 만든다.
4.1 Python: 프롬프트 캐시 + 결과 캐시
import hashlib, json, time
from typing import Dict
from redis import Redis
r = Redis(host="localhost", port=6379)
def norm(q: str) -> str:
return " ".join(q.lower().strip().split())
def cache_key(ns: str, tenant: str, model: str, pver: str, params: Dict, user_input: str) -> str:
payload = json.dumps({"p":params, "u":norm(user_input)}, sort_keys=True)
h = hashlib.sha256(payload.encode()).hexdigest()[:16]
return f"{ns}:{tenant}:{model}:{pver}:{h}"
TTL = 60*60*12 # 12h
def ask_with_cache(user_input: str) -> str:
key = cache_key("llm", "acme", "gpt-x", "p3", {"t":0.2}, user_input)
cached = r.get(key)
if cached:
return cached.decode()
# TODO: 실제 LLM 호출부
answer = f"[mock] answer to: {user_input}"
r.setex(key, TTL, answer)
return answer
4.2 Node.js: 임베딩 캐시
import crypto from "crypto";
import { createClient } from "redis";
const redis = createClient();
function contentHash(text: string) {
return crypto.createHash("sha256").update(text).digest("hex").slice(0,16);
}
async function embedWithCache(text: string, model = "text-emb-x") {
const key = `emb:acme:${model}:${contentHash(text)}`;
const hit = await redis.get(key);
if (hit) return JSON.parse(hit);
// TODO: 실제 임베딩 API 호출
const vec = Array.from({length: 8}, (_,i)=>Math.random());
await redis.setEx(key, 60*60*24*30, JSON.stringify({model, vec})); // 30d
return { model, vec };
}
4.3 검색 캐시: 후보·리랭킹 분리 저장
- retr:... 키에는 BM25/벡터 top-k 후보와 스코어를 저장.
- rerank:... 키에는 크로스 인코더 재점수화 결과를 저장.
- 인용 문서 해시와 필터(제품/버전/팀)를 포함해 권한 경계를 유지.

5. 관찰성·A/B·비용 계산법
핵심 요약: 캐시율이 아니라 "절감된 토큰/초"를 본다.
5.1 핵심 지표
- Hit Rate(%): (hit / total)
- Saved Tokens / sec: 캐시 히트로 절감된 입력/출력 토큰 수
- p50/p95 Latency 개선(%): 캐시 적용 전후 비교
- Stale Ratio(%): 만료 전 응답 비율(SWR 운영 시)
5.2 A/B 실험
- 테넌트 또는 사용자 10~20%에 대해 캐시 미사용 그룹을 두고 차이를 측정.
- 프롬프트 버전 변경 시 자동으로 새로운 키 스페이스로 이동하도록 설계.
5.3 비용 계산(간단식)
월 절감액 ≈ (평균 요청수 × 평균 토큰 × 단가 × HitRate) + (모델 지연 감소로 절감된 인프라비)
- 레디스/키밸류 스토리지 비용을 반영하여 순절감액을 산출.

6. FAQ와 체크리스트
핵심 요약: "과유불급"—캐시보다 무효화 전략이 더 어렵다.
Q. LLM 캐시가 환각을 고착시키지 않나?
A. 출처·버전 해시를 키에 포함하고, SWR로 백그라운드 갱신을 돌리면 위험이 낮습니다.
Q. 개인화는 어떻게?
A. 키에 사용자/조직 ID를 넣거나, 공통 부분은 공유 캐시 + 개인화 레이어는 별도 캐시.
Q. 무엇부터 도입?
A. 프롬프트 캐시부터 시작 → 결과 캐시 → 임베딩/검색 캐시 순으로 확장.
체크리스트
- 키 스키마/버전 규칙 수립(ns:tenant:model:promptVer:paramHash:inputHash)
- TTL 정책(정적/반정적/동적) 정의
- 무효화 경로(수동 퍼지·이벤트 퍼지·SWR) 정의
- RAG 해시·권한 경계 포함
- 모니터링 대시보드(히트율·절감 토큰·지연·Stale)
결론
핵심 요약: 작은 캐시 레이어 하나가 팀 전체 비용 구조를 바꾼다.
LLM 캐시를 "한 덩어리"로 보지 말고, KV 캐시·프롬프트 캐시·결과 캐시·임베딩 캐시·검색 캐시라는 5가지 레이어로 분리하세요. 키·TTL·무효화·버전을 명확히 규정하고, 관찰 가능한 지표를 운영에 연결하면 지연과 비용이 동시에 내려갑니다. 오늘 제시한 표준 래퍼와 키 설계만 적용해도 지연·비용 30~50% 절감을 체감할 수 있을 것입니다.
함께 보면 좋은 글
LLM 함수 호출(Function Calling) 완전 가이드: JSON Schema·툴 사용·에러 복구
LLM 함수 호출(Function Calling) 완전 가이드: JSON Schema·툴 사용·에러 복구 LLM 함수 호출을 올바르게 설계하면 모델이 정확한 구조화 응답을 내고, 외부 API·DB·검색·계산 같은 툴 사용을 안전하게 자
tapyst.com
프롬프트 주입 방어 완전 가이드: 안전한 RAG·툴 호출을 위한 4계층 보안 아키텍처
프롬프트 주입 방어 완전 가이드: 안전한 RAG·툴 호출을 위한 4계층 보안 아키텍처 프롬프트 주입 방어는 2025년 AI 제품 개발의 필수 역량입니다. 이 글은 프롬프트 주입 방어를 중심으로 데이터·
tapyst.com
2025년, AI 에이전트를 프로덕션에 넣는 가장 현실적인 방법: 아키텍처·RAG·평가·비용 최적화까지
2025년, AI 에이전트를 프로덕션에 넣는 가장 현실적인 방법: 아키텍처·RAG·평가·비용 최적화까지AI 에이전트를 올해 안에 실제 서비스로 돌리고 싶다면, 무엇부터 설계해야 할까요? 이 글은 2025
tapyst.com
'개발 · IT > IT 트렌드 & 생산성' 카테고리의 다른 글
| LangGraph 멀티에이전트 워크플로 구축: 설계·패턴·RAG·운영까지 (완전 가이드) (1) | 2025.08.30 |
|---|---|
| vLLM 서빙 완전 가이드: FastAPI·Kubernetes·RAG 결합으로 초저비용 고속 배포 (3) | 2025.08.29 |
| 프롬프트 주입 방어 완전 가이드: 안전한 RAG·툴 호출을 위한 4계층 보안 아키텍처 (3) | 2025.08.27 |
| AI 에이전트 실전 구축 가이드: 2025 워크플로우·도구·운영 전략 (4) | 2025.08.26 |
| LLM 함수 호출(Function Calling) 완전 가이드: JSON Schema·툴 사용·에러 복구 (2) | 2025.08.25 |



